China Reaches New Stage in AI Race: LongCat-2.0 Unveiled
China's Meituan company has officially unveiled the LongCat-2.0 model, causing a stir in the world of artificial intelligence. This news is not just about another neural network, but it has entered history as the world's first trillion-parameter large language model (LLM) trained entirely on domestic Chinese chips. Despite Western technological restrictions, this project proves that China can create top-tier software products by relying on its own independent computing power. This is reported by Ixbt.com news reports.
LongCat-2.0 impresses with its technical specifications: the model has 1.6 trillion parameters and can process a massive context of up to 1 million tokens. For comparison, this is equivalent to reading several volumes of a book and analyzing the information within them simultaneously. According to ixbt.com, the training process was carried out on a cluster consisting of 50,000 domestic ASIC accelerators. Experts link this infrastructure to the Huawei ecosystem, demonstrating China's independence in the hardware sector.
Agent Capabilities and Technical Innovations
LongCat-2.0 is not just a text-writing bot, but was developed as an "agent" capable of performing complex tasks. It can write and edit code, work with various API services, and implement multi-step logical chains. The model's training base includes over 30 trillion tokens, enriched with multilingual data and programming code. This makes it one of the most powerful models on the global market.Technically, LongCat-2.0 utilizes the "LongCat Sparse Attention" (LSA) mechanism. This technology allows the model to focus only on the most important parts when processing huge texts, which drastically reduces computational complexity. Additionally, the model is based on the "Mixture of Experts" (MoE) architecture, activating only the necessary neurons for each request. While simple tasks consume fewer resources, full power is mobilized for complex problems.
The MOPD (Multi-Teacher On-Policy Distill) method was used in the model's training. In this process, several specialized "teacher" models provide knowledge to a single system. As a result, LongCat-2.0 shows high performance in three directions:
- Agent experts — working with tools and API;
- Logic experts — complex STEM and logical problems;
- Interactive experts — strict adherence to instructions and error reduction.
Competition and Practical Results
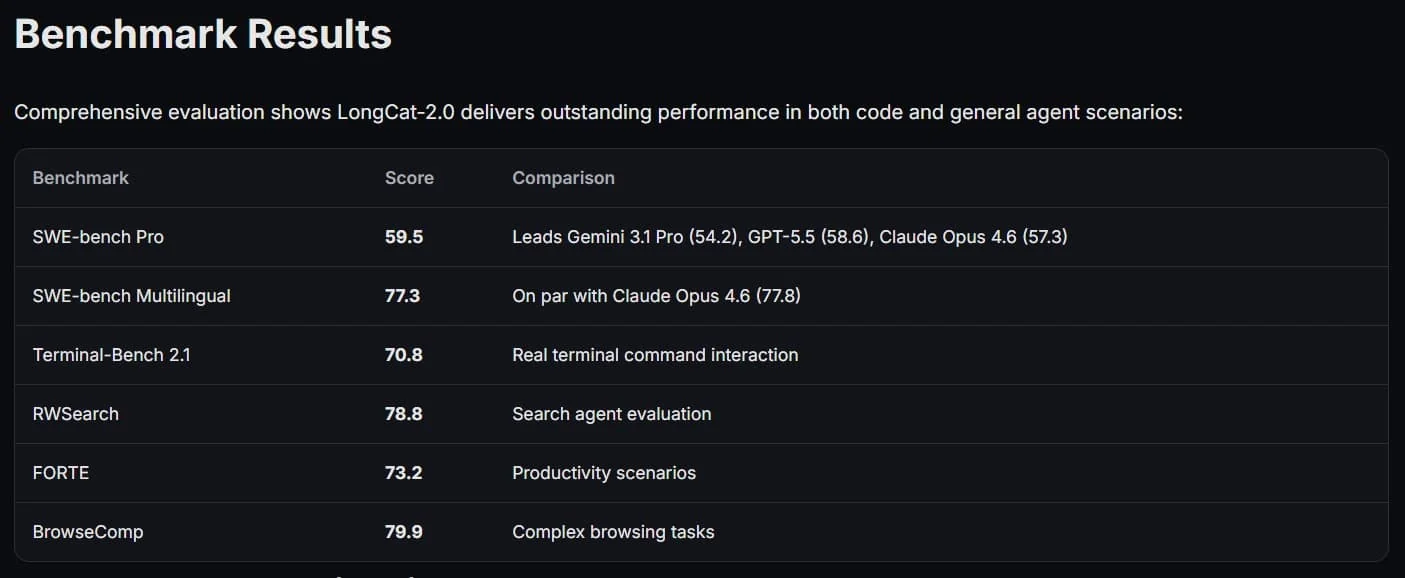
In conducted tests, LongCat-2.0 showed it can keep up with its competitors. In the SWE-bench Pro rating, it scored 59.5 points, surpassing Google's Gemini 3.1 Pro and approaching the level of leading models like GPT-5.5 from OpenAI and Claude Opus from Anthropic. Its results in coding and working with web agents were particularly highly rated.In practice, LongCat-2.0 can be used to create full web applications based on a single description, build SQL agents, and form interactive 3D scenes using the Three.js library. Such achievements signify how serious China's strategic goals in the field of AI are. Now, training trillion-parameter models has become not just an experiment but a practical reality, which is bound to shift the balance in the global technology market.






















Comments 0
…