Китай вышел на новый этап в гонке ИИ: представлен ЛонгКат-2.0
Китайская компания Меитуан официально представила модель ЛонгКат-2.0, вызвавшую резонанс в мире искусственного интеллекта. Эта новинка — не просто очередная нейросеть, а первая в мире большая языковая модель (LLM) с триллионом параметров, полностью обученная на отечественных китайских чипах. Данный проект доказывает, что, несмотря на технологические ограничения Запада, Китай способен создавать программные продукты высочайшего уровня, опираясь на собственные вычислительные мощности. Об этом сообщает Иксбт.ком сообщает в материале.
ЛонгКат-2.0 впечатляет своими техническими характеристиками: модель обладает 1,6 триллиона параметров и способна обрабатывать гигантский контекст до 1 миллиона токенов. Для сравнения, это эквивалентно одновременному прочтению и анализу нескольких томов книги. По данным иксбт.ком, процесс обучения модели проходил в кластере из 50 тысяч отечественных АСИК-ускорителей. Эксперты связывают эту инфраструктуру с экосистемой Huawei, что подчеркивает независимость Китая в сфере аппаратного обеспечения.
Агентские возможности и технические инновации
ЛонгКат-2.0 разработан не просто как чат-бот для написания текстов, а как «агент» для выполнения сложных задач. Он может писать и редактировать код, взаимодействовать с различными АПИ-сервисами и реализовывать многошаговые логические цепочки. Обучающая база модели включает более 30 триллионов токенов, обогащенных многоязычными данными и программным кодом, что делает её одной из самых мощных моделей на глобальном рынке.Технически ЛонгКат-2.0 использует механизм «ЛонгКат Спарсе Аттентион» (ЛСА). Эта технология позволяет модели при обработке огромных текстов фокусироваться только на самых важных частях, что резко снижает вычислительную сложность. Кроме того, модель основана на архитектуре «Микстуре оф Экспертс» (МоЭ), которая активирует только необходимые нейроны для каждого конкретного запроса. Простые задачи требуют меньше ресурсов, тогда как для сложных проблем задействуется вся мощность.
При обучении модели был применен метод МОПД (Мулти-Теачер Он-Поликй Дистилл). В этом процессе несколько специализированных моделей-«учителей» передают знания единой системе. В результате ЛонгКат-2.0 демонстрирует высокие результаты в трех направлениях:
- Агентские эксперты — работа с инструментами и API;
- Логические эксперты — сложные СТЭМ-задачи и логические вопросы;
- Интерактивные эксперты — точное следование инструкциям и минимизация ошибок.
Конкуренция и практические результаты
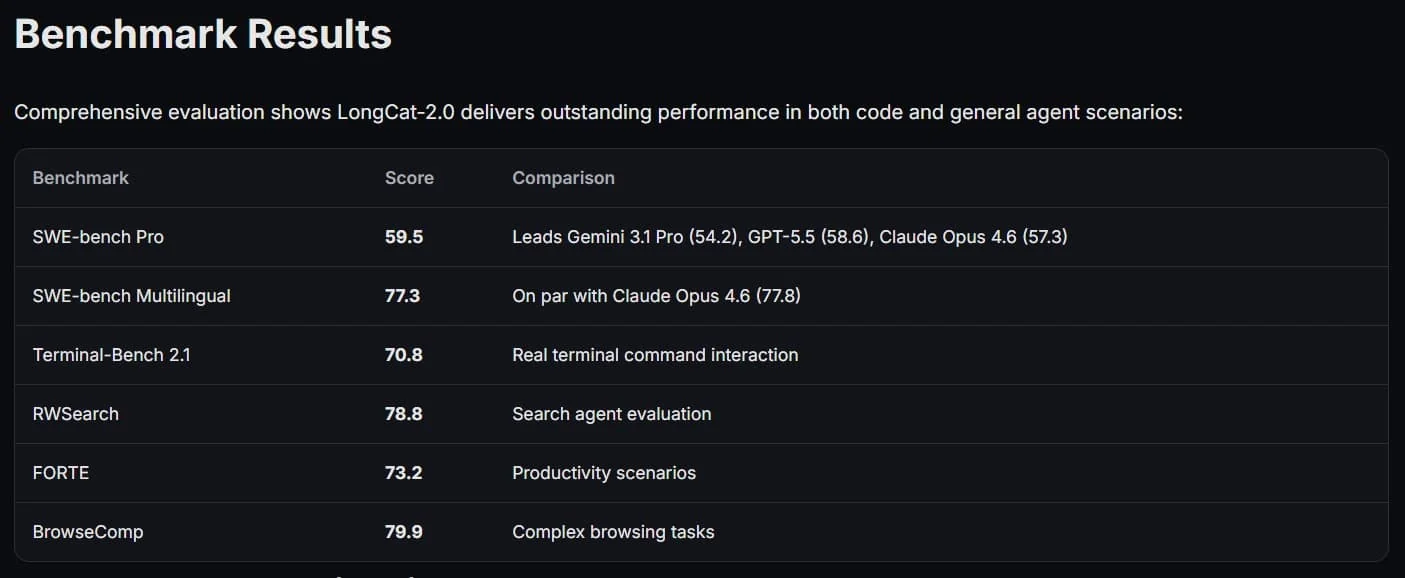
В проведенных тестах ЛонгКат-2.0 показал, что не уступает своим конкурентам. В рейтинге СВЭ-бенч Pro модель набрала 59,5 балла, опередив Gemini 3.1 Pro от Google и приблизившись к уровню ведущих моделей, таких как GPT-5.5 от OpenAI и Claude Опус от Anthropic. Особенно высоко были оценены результаты в написании кода и работе с веб-агентами.На практике с помощью ЛонгКат-2.0 можно создавать полноценные веб-приложения на основе одного описания, строить СКЛ-агентов и формировать интерактивные 3Д-сцены в библиотеке Три.джс. Такие достижения говорят о серьезности стратегических целей Китая в области ИИ. Теперь обучение моделей с триллионом параметров стало не просто экспериментом, а практической реальностью, что неизбежно изменит баланс на мировом технологическом рынке.






















Комментарии 0
…