China erreicht neue Stufe im KI-Wettlauf: LongCat-2.0 vorgestellt
Das chinesische Unternehmen Meituan hat offiziell das Modell LongCat-2.0 vorgestellt, das in der Welt der künstlichen Intelligenz für Aufsehen sorgt. Diese Neuigkeit ist nicht einfach nur ein weiteres neuronales Netzwerk, sondern ist als das weltweit erste Large Language Model (LLM) mit einer Billion Parametern in die Geschichte eingegangen, das vollständig auf einheimischen chinesischen Chips trainiert wurde. Trotz westlicher technologischer Beschränkungen beweist dieses Projekt, dass China in der Lage ist, High-End-Softwareprodukte zu schaffen, indem es auf seine eigenen unabhängigen Rechenkapazitäten setzt. Dies berichtet Ixbt.com Nachrichten berichtet.
LongCat-2.0 beeindruckt durch seine technischen Daten: Das Modell verfügt über 1,6 Billionen Parameter und kann einen riesigen Kontext von bis zu 1 Million Token verarbeiten. Zum Vergleich: Dies entspricht dem gleichzeitigen Lesen mehrerer Buchbände und der Analyse der darin enthaltenen Informationen. Laut ixbt.com wurde der Trainingsprozess auf einem Cluster aus 50.000 einheimischen ASIC-Beschleunigern durchgeführt. Experten bringen diese Infrastruktur mit dem Huawei-Ökosystem in Verbindung, was Chinas Unabhängigkeit im Hardware-Sektor unterstreicht.
Agenten-Fähigkeiten und technische Innovationen
LongCat-2.0 ist nicht nur ein Bot zum Schreiben von Texten, sondern wurde als "Agent" für die Ausführung komplexer Aufgaben entwickelt. Er kann Code schreiben, bearbeiten, mit verschiedenen API-Diensten interagieren und mehrstufige logische Ketten implementieren. Die Trainingsbasis des Modells umfasst über 30 Billionen Token, angereichert mit mehrsprachigen Daten und Programmiercodes. Dies macht es zu einem der leistungsstärksten Modelle auf dem globalen Markt.Technisch nutzt LongCat-2.0 den "LongCat Sparse Attention" (LSA)-Mechanismus. Diese Technologie ermöglicht es dem Modell, bei der Verarbeitung riesiger Texte nur auf die wichtigsten Teile zu achten, was die Rechenkomplexität drastisch reduziert. Zudem basiert das Modell auf der "Mixture of Experts" (MoE)-Architektur, bei der für jede Anfrage nur die benötigten Neuronen aktiviert werden. Während einfache Aufgaben weniger Ressourcen verbrauchen, wird für komplexe Probleme die volle Leistung mobilisiert.
Beim Training des Modells wurde die MOPD (Multi-Teacher On-Policy Distill)-Methode angewandt. In diesem Prozess vermitteln mehrere spezialisierte "Lehrer"-Modelle ihr Wissen an ein einziges System. Infolgedessen zeigt LongCat-2.0 in drei Bereichen hohe Ergebnisse:
- Agenten-Experten — Arbeit mit Tools und API;
- Logik-Experten — komplexe STEM- und Logikprobleme;
- Interaktive Experten — präzise Befolgung von Anweisungen und Fehlerreduzierung.
Wettbewerb und praktische Ergebnisse
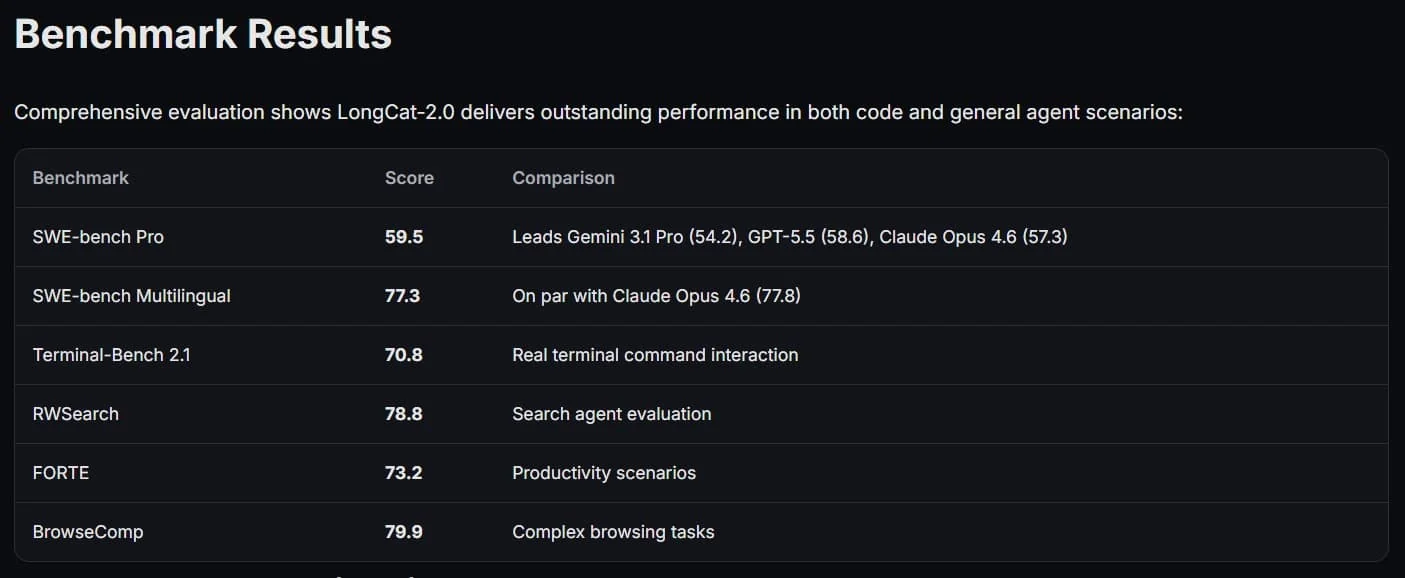
In durchgeführten Tests zeigte LongCat-2.0, dass es mit seinen Konkurrenten mithalten kann. Im SWE-bench Pro-Ranking erreichte es 59,5 Punkte, übertraf damit das Gemini 3.1 Pro Modell von Google und näherte sich führenden Modellen wie GPT-5.5 von OpenAI und Claude Opus von Anthropic an. Besonders in der Codierung und der Arbeit mit Web-Agenten wurden die Ergebnisse hoch bewertet.In der Praxis können mit LongCat-2.0 auf Basis einer einzigen Beschreibung vollständige Web-Apps erstellt, SQL-Agenten gebaut und interaktive 3D-Szenen in der Three.js-Bibliothek geformt werden. Solche Erfolge zeigen, wie ernst Chinas strategische Ziele im Bereich der KI sind. Das Training von Modellen mit einer Billion Parametern ist nun nicht mehr nur ein Experiment, sondern eine praktische Realität, die das Gleichgewicht auf dem globalen Technologiemarkt verändern wird.

















Kommentare 0
…