La Chine franchit une nouvelle étape dans la course à l'IA : présentation de LongCat-2.0
L'entreprise chinoise Meituan a officiellement présenté LongCat-2.0, un modèle qui fait sensation dans le monde de l'intelligence artificielle. Cette nouveauté n'est pas simplement un réseau neuronal de plus, mais elle entre dans l'histoire comme le premier grand modèle de langage (LLM) d'un billion de paramètres entraîné entièrement sur des puces chinoises locales. Ce projet prouve que, malgré les restrictions technologiques de l'Occident, la Chine peut créer des produits logiciels de haut niveau en s'appuyant sur ses propres capacités de calcul. C'est ce qu'indique Ixbt.com dans son article.
LongCat-2.0 impressionne par ses spécifications techniques : le modèle possède 1,6 billion de paramètres et peut traiter un contexte massif allant jusqu'à 1 million de tokens. À titre de comparaison, cela équivaut à lire et analyser les données de plusieurs volumes de livres simultanément. Selon ixbt.com, le processus d'entraînement a été réalisé sur un cluster composé de 50 000 accélérateurs ASIC locaux. Les experts associent cette infrastructure à l'écosystème Huawei, illustrant l'indépendance de la Chine dans le domaine du matériel.
Capacités d'agent et innovations techniques
LongCat-2.0 n'est pas un simple bot d'écriture de texte, mais a été conçu comme un « agent » capable d'exécuter des tâches complexes. Il peut écrire et éditer du code, interagir avec divers services API et mettre en œuvre des chaînes logiques multi-étapes. La base d'entraînement du modèle comprend plus de 30 billions de tokens, enrichis de données multilingues et de codes de programmation, ce qui en fait l'un des modèles les plus puissants du marché mondial.Techniquement, LongCat-2.0 utilise le mécanisme « LongCat Sparse Attention » (LSA). Cette technologie permet au modèle de se concentrer uniquement sur les parties les plus importantes lors du traitement de textes massifs, réduisant ainsi considérablement la complexité du calcul. De plus, le modèle est basé sur l'architecture « Mixture of Experts » (MoE), n'activant que les neurones nécessaires pour chaque requête. Les tâches simples consomment moins de ressources, tandis que toute la puissance est mobilisée pour les problèmes complexes.
La méthode MOPD (Multi-Teacher On-Policy Distill) a été appliquée pour l'entraînement du modèle. Dans ce processus, plusieurs modèles « enseignants » spécialisés transmettent leurs connaissances à un système unique. En conséquence, LongCat-2.0 affiche des performances élevées dans trois domaines :
- Experts agents — interaction avec les outils et les API ;
- Experts logiques — problèmes STEM et logiques complexes ;
- Experts interactifs — respect précis des instructions et réduction des erreurs.
Concurrence et résultats pratiques
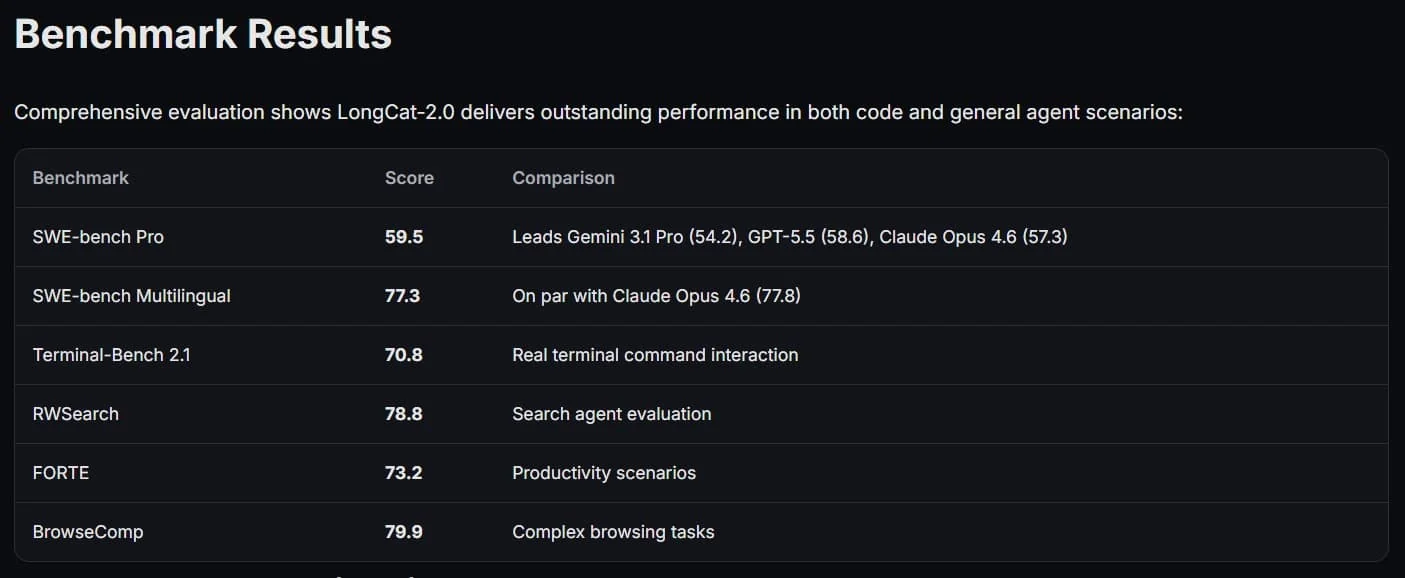
Lors des tests effectués, LongCat-2.0 a montré qu'il ne cédait pas face à ses concurrents. Dans le classement SWE-bench Pro, il a obtenu 59,5 points, dépassant le modèle Gemini 3.1 Pro de Google et se rapprochant des modèles leaders comme GPT-5.5 d'OpenAI et Claude Opus d'Anthropic. Ses résultats ont été particulièrement salués dans l'écriture de code et le travail avec les agents web.En pratique, LongCat-2.0 permet de créer des applications web complètes à partir d'une seule description, de construire des agents SQL et de générer des scènes 3D interactives avec la bibliothèque Three.js. De tels accomplissements montrent à quel point les objectifs stratégiques de la Chine dans le domaine de l'IA sont sérieux. Désormais, l'entraînement de modèles d'un billion de paramètres n'est plus une expérience, mais une réalité pratique, ce qui est destiné à modifier l'équilibre du marché technologique mondial.

















Commentaires 0
…