Çin Yapay Zeka Yarışında Yeni Bir Aşamaya Geçti: LongCat-2.0 Tanıtıldı
Çinli Meituan şirketi, yapay zeka dünyasında yankı uyandıran LongCat-2.0 modelini resmi olarak tanıttı. Bu yenilik sadece sıradan bir sinir ağı değil, aynı zamanda tamamen yerli Çin çiplerinde eğitilen dünyadaki ilk trilyon parametreli büyük dil modeli (LLM) olarak tarihe geçti. Bu proje, Batı'nın teknolojik kısıtlamalarına rağmen Çin'in kendi bağımsız hesaplama güçlerine dayanarak en üst düzey yazılım ürünleri yaratabileceğini kanıtlıyor. Ixbt.com haber veriyor.
LongCat-2.0 teknik özellikleriyle hayran bırakıyor: model 1,6 trilyon parametreye sahip ve 1 milyon token'a kadar devasa bir bağlamı işleyebiliyor. Karşılaştırmak gerekirse, bu durum aynı anda birkaç ciltlik kitabı okuyup içindeki verileri analiz etmekle eşdeğerdir. ixbt.com verilerine göre, modelin eğitim süreci 50 bin yerli ASIC hızlandırıcıdan oluşan bir kümede gerçekleştirildi. Uzmanlar bu altyapıyı Huawei ekosistemi ile ilişkilendiriyor, bu da Çin'in donanım alanındaki bağımsızlığını gösteriyor.
Ajan yetenekleri ve teknik inovasyonlar
LongCat-2.0 sadece metin yazan bir bot değil, karmaşık görevleri yerine getiren bir "ajan" olarak geliştirildi. Kod yazabilir, düzenleyebilir, çeşitli API servisleriyle çalışabilir ve çok aşamalı mantıksal zincirleri gerçekleştirebilir. Modelin eğitim veri seti 30 trilyondan fazla token içeriyor ve çok dilli veriler ile programlama kodlarıyla zenginleştirilmiş. Bu da onu küresel pazardaki en güçlü modellerden biri haline getiriyor.Teknik açıdan LongCat-2.0 "LongCat Sparse Attention" (LSA) mekanizmasını kullanıyor. Bu teknoloji, modelin devasa metinleri işlerken sadece en önemli kısımlara odaklanmasını sağlayarak hesaplama karmaşıklığını önemli ölçüde azaltıyor. Ayrıca model "Mixture of Experts" (MoE) mimarisine dayanıyor ve her istek için sadece gerekli nöronları etkinleştiriyor. Basit görevler daha az kaynak tüketirken, karmaşık problemler için tüm güç seferber ediliyor.
Modelin eğitiminde MOPD (Multi-Teacher On-Policy Distill) yöntemi uygulandı. Bu süreçte birden fazla uzmanlaşmış "öğretmen" model tek bir sisteme bilgi aktarıyor. Sonuç olarak LongCat-2.0 üç yönde yüksek performans sergiliyor:
- Ajan uzmanları — araçlar ve API ile çalışma;
- Mantık uzmanları — karmaşık STEM ve mantıksal problemler;
- İnteraktif uzmanlar — talimatlara kesin uyum ve hataların azaltılması.
Rekabet ve pratik sonuçlar
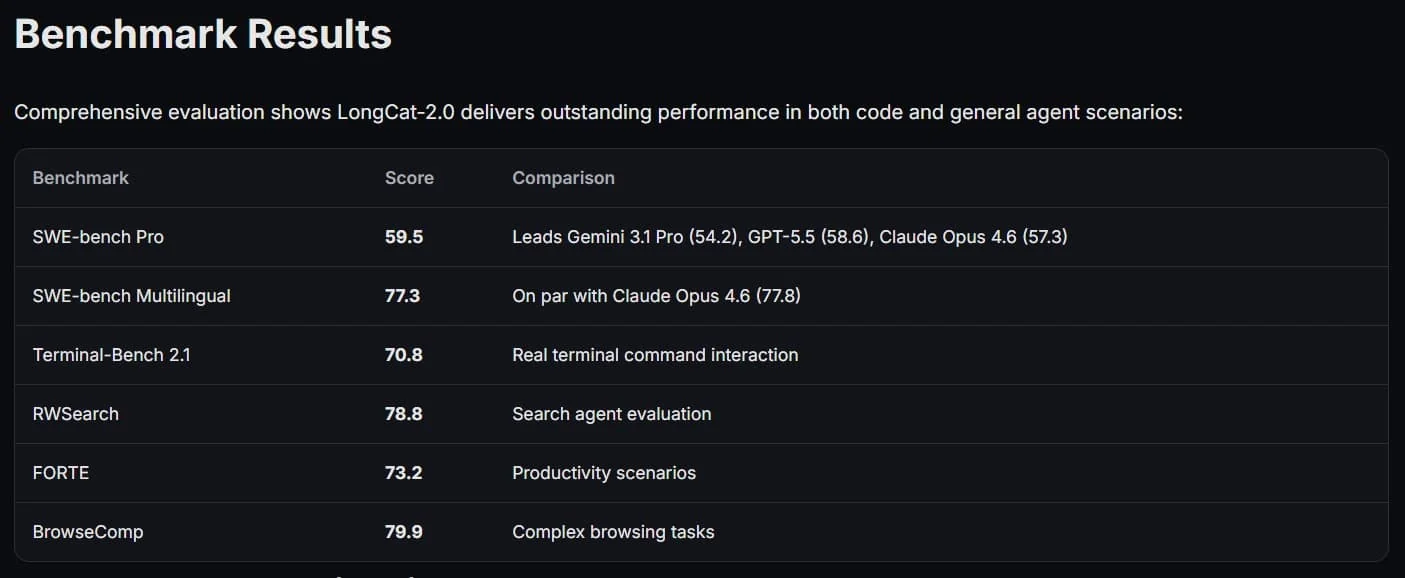
Yapılan testlerde LongCat-2.0 rakiplerinin gerisinde kalmadığını gösterdi. SWE-bench Pro sıralamasında 59,5 puan toplayarak Google'ın Gemini 3.1 Pro modelini geride bıraktı ve OpenAI ile Anthropic'in GPT-5.5 ve Claude Opus gibi öncü modellerinin seviyesine yaklaştı. Özellikle kod yazma ve web ajanlarıyla çalışma konusundaki sonuçları yüksek değerlendirildi.Pratikte LongCat-2.0 yardımıyla tek bir açıklama ile tam web uygulamaları oluşturmak, SQL ajanları kurmak ve Three.js kütüphanesinde interaktif 3D sahneler oluşturmak mümkün. Bu tür başarılar, Çin'in yapay zeka alanındaki stratejik hedeflerinin ne kadar ciddi olduğunu gösteriyor. Artık trilyon parametreli modelleri eğitmek sadece bir deney değil, pratik bir gerçeklik haline geldi ve bu durum küresel teknoloji pazarındaki dengeyi değiştirmeye aday.





















Yorumlar 0
…