Anthropic Claude Opus 4.8 Introduced
Anthropic has introduced Claude Opus 4.8, an update to its flagship model that promises significant improvements in code accuracy. Priced the same as its predecessor at $5 per million input tokens and $25 per million output tokens, this release is described by the company as a modest but significant improvement over Opus 4.7. This is reported by Habr.com .
A standout feature of Claude Opus 4.8 is its ability to more effectively identify and fix its own code errors. According to internal metrics, the model overlooks four times fewer errors compared to the previous version. This addresses a common issue with large language models, as they often jump to conclusions and confidently report success without sufficient evidence.
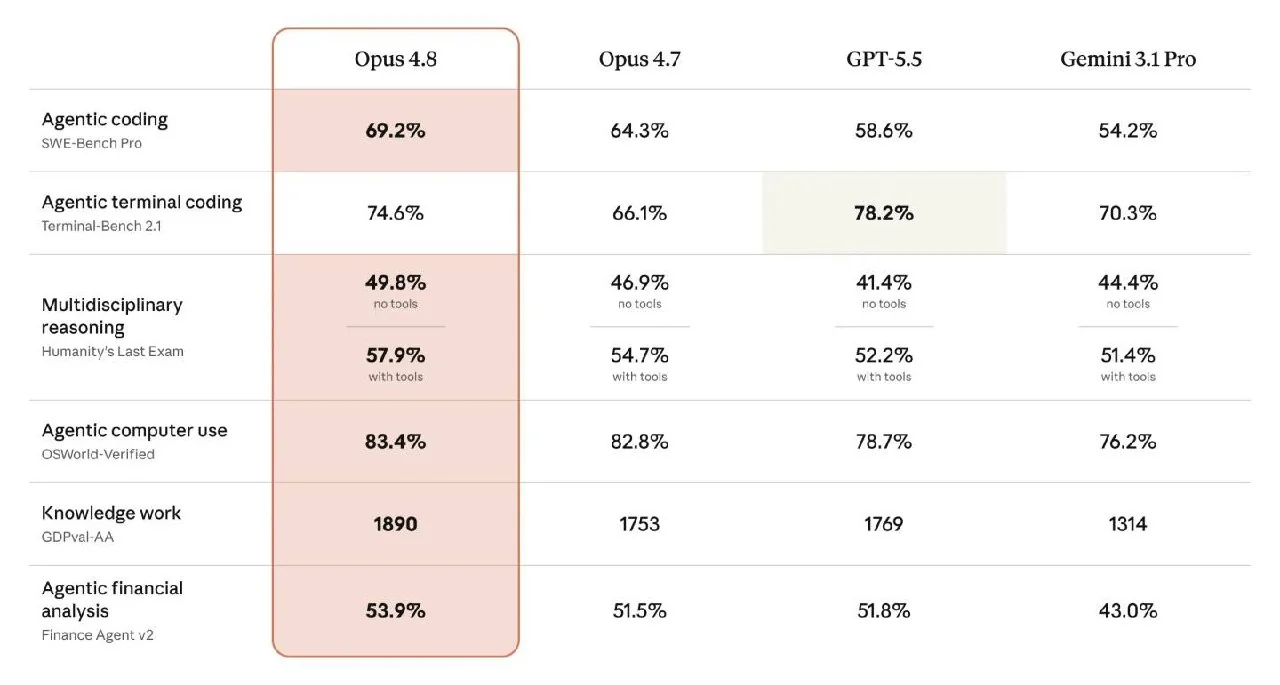
Despite modest improvements, Claude Opus 4.8 shows high results across various benchmarks. It scored 69.2% on SWE-Bench Pro for agentic programming, surpassing Opus 4.7's 64.3%. It achieved 83.4% on OSWorld-Verified for computer control and scored 1890 on the GDPval-AA knowledge assessment, outperforming GPT-5.5's 1769. However, it scored 74.6% on Terminal-Bench for terminal coding, lower than GPT-5.5's 78.2%.
Anthropic also highlighted the model's improved safety, indicating reduced tendencies for deception or misuse. Claude Opus 4.8 nearly matches the experimental Claude Mythos Preview in this regard, showing significant progress in aligning model behavior with ethical standards.
























Comments 0
…