China alcanza una nueva etapa en la carrera de la IA: se presenta LongCat-2.0
La empresa china Meituan ha presentado oficialmente LongCat-2.0, un modelo que ha causado sensación en el mundo de la inteligencia artificial. Esta novedad no es simplemente otra red neuronal, sino que entra en la historia como el primer modelo de lenguaje extenso (LLM) de un billón de parámetros entrenado completamente en chips chinos locales. Este proyecto demuestra que, a pesar de las restricciones tecnológicas de Occidente, China puede crear productos de software de más alto nivel apoyándose en sus propias capacidades de cómputo. Así lo informa Ixbt.com en su noticia.
LongCat-2.0 impresiona con sus especificaciones técnicas: el modelo cuenta con 1,6 billones de parámetros y puede procesar un contexto masivo de hasta 1 millón de tokens. Para comparar, esto equivale a leer y analizar la información de varios volúmenes de libros simultáneamente. Según ixbt.com, el proceso de entrenamiento se llevó a cabo en un clúster compuesto por 50 000 aceleradores ASIC locales. Los expertos vinculan esta infraestructura con el ecosistema de Huawei, lo que demuestra la independencia de China en el sector del hardware.
Capacidades de agente e innovaciones técnicas
LongCat-2.0 no es solo un bot que escribe texto, sino que ha sido desarrollado como un «agente» que ejecuta tareas complejas. Puede escribir y editar código, trabajar con diversos servicios API y realizar cadenas lógicas de múltiples pasos. La base de entrenamiento del modelo incluye más de 30 billones de tokens, enriquecida con datos multilingües y códigos de programación, lo que lo convierte en uno de los modelos más potentes del mercado global.Técnicamente, LongCat-2.0 utiliza el mecanismo «LongCat Sparse Attention» (LSA). Esta tecnología permite al modelo centrarse solo en las partes más importantes al procesar textos masivos, reduciendo drásticamente la complejidad computacional. Además, el modelo se basa en la arquitectura «Mixture of Experts» (MoE), activando solo las neuronas necesarias para cada solicitud. Mientras que las tareas sencillas consumen menos recursos, para los problemas complejos se moviliza toda la potencia.
En el entrenamiento del modelo se aplicó el método MOPD (Multi-Teacher On-Policy Distill). En este proceso, varios modelos «maestros» especializados transmiten conocimientos a un único sistema. Como resultado, LongCat-2.0 muestra resultados elevados en tres direcciones:
- Expertos agentes: trabajo con herramientas y API;
- Expertos lógicos: problemas complejos de STEM y lógica;
- Expertos interactivos: seguimiento preciso de instrucciones y reducción de errores.
Competencia y resultados prácticos
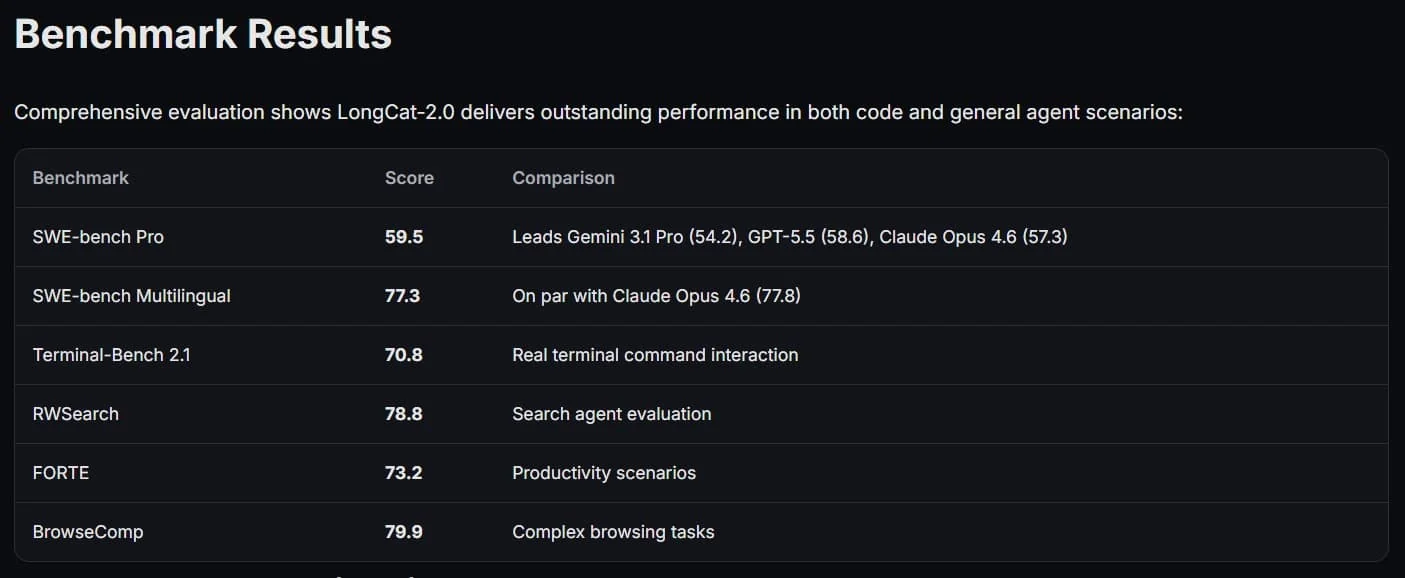
En las pruebas realizadas, LongCat-2.0 demostró que no se queda atrás frente a sus competidores. En el ranking SWE-bench Pro, obtuvo 59,5 puntos, superando al modelo Gemini 3.1 Pro de Google y acercándose al nivel de modelos líderes como GPT-5.5 de OpenAI y Claude Opus de Anthropic. Sus resultados fueron especialmente valorados en la escritura de código y el trabajo con agentes web.En la práctica, con la ayuda de LongCat-2.0 es posible crear aplicaciones web completas basadas en una sola descripción, construir agentes SQL y formar escenas 3D interactivas en la biblioteca Three.js. Logros como este significan cuán serios son los objetivos estratégicos de China en el campo de la inteligencia artificial. Ahora, el entrenamiento de modelos de un billón de parámetros ya no es solo un experimento, sino una realidad práctica, lo que inevitablemente cambiará el equilibrio en el mercado tecnológico mundial.

















Comentarios 0
…