Anthropic Claude Opus 4.8 presentado
Anthropic ha presentado Claude Opus 4.8, una actualización de su modelo principal que promete mejoras significativas en la precisión del código. Con el mismo precio que su predecesor, es decir, 5 $ por millón de tokens de entrada y 25 $ por millón de tokens de salida, esta versión es descrita por la empresa como una mejora modesta pero notable respecto a Opus 4.7. Así lo informa Habr.com .
Una característica destacada de Claude Opus 4.8 es su capacidad para identificar y corregir de manera más efectiva sus propios errores de código. Según las mediciones internas, el modelo pasa por alto cuatro veces menos errores en comparación con la versión anterior. Esto soluciona un problema común con los modelos de lenguaje grandes, ya que a menudo sacan conclusiones precipitadas e informan del éxito con confianza sin pruebas suficientes.
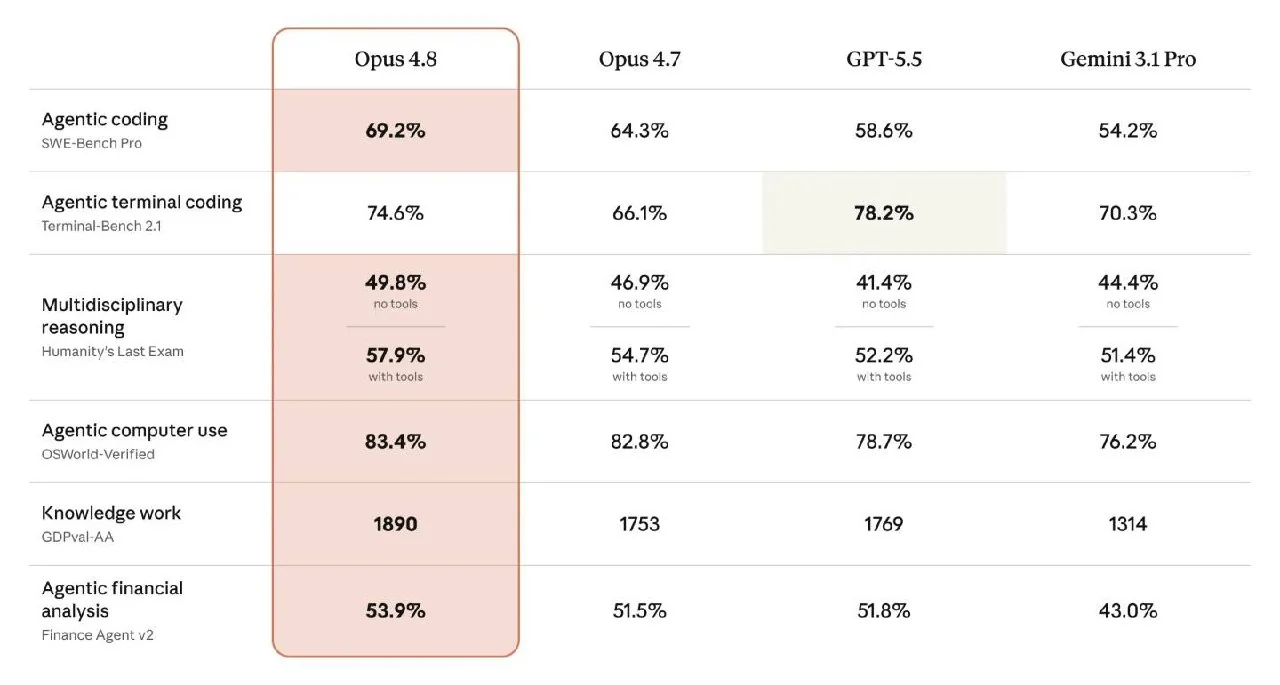
A pesar de las mejoras modestas, Claude Opus 4.8 muestra resultados altos en varios benchmarks. Obtuvo un 69,2 % en SWE-Bench Pro para programación de agentes, superando el 64,3 % de Opus 4.7. Alcanzó el 83,4 % en OSWorld-Verified para control informático y obtuvo 1890 puntos en la evaluación de conocimientos GDPval-AA, superando los 1769 puntos de GPT-5.5. Sin embargo, obtuvo un 74,6 % en Terminal-Bench para codificación de terminal, un resultado inferior al 78,2 % de GPT-5.5.
Anthropic también destacó la seguridad mejorada del modelo, lo que indica una reducción en las tendencias de engaño o mal uso. Claude Opus 4.8 casi iguala al experimental Claude Mythos Preview en este aspecto, mostrando un progreso significativo en la alineación del comportamiento del modelo con los estándares éticos.


















Comentarios 0
…