Anthropic Claude Opus 4.8 présenté
Anthropic a présenté Claude Opus 4.8, une mise à jour de son modèle phare qui promet des améliorations significatives de la précision du code. Au même prix que la version précédente, soit 5 $ par million de jetons d'entrée et 25 $ par million de jetons de sortie, cette version est décrite par l'entreprise comme une amélioration modeste mais notable par rapport à Opus 4.7. C'est ce que rapporte Habr.com .
Une caractéristique marquante de Claude Opus 4.8 est sa capacité à identifier et à corriger plus efficacement ses propres erreurs de code. Selon les mesures internes, le modèle ignore quatre fois moins d'erreurs que la version précédente. Cela résout un problème courant avec les grands modèles de langage, car ils tirent souvent des conclusions hâtives et signalent le succès avec assurance sans preuves suffisantes.
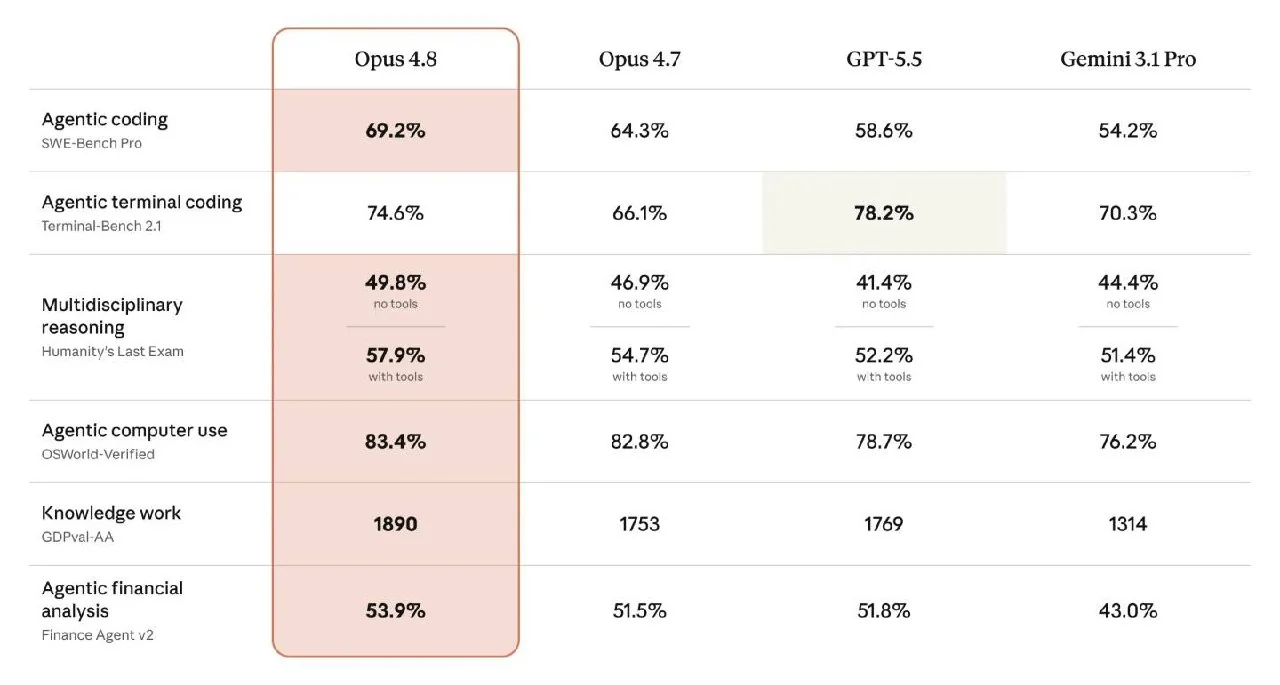
Malgré des améliorations modestes, Claude Opus 4.8 affiche des résultats élevés sur divers benchmarks. Il a obtenu 69,2 % sur SWE-Bench Pro pour la programmation agentique, dépassant les 64,3 % d'Opus 4.7. Il atteint 83,4 % sur OSWorld-Verified pour le contrôle informatique et obtient 1890 points à l'évaluation des connaissances GDPval-AA, surpassant les 1769 points de GPT-5.5. Cependant, il obtient 74,6 % sur Terminal-Bench pour le codage terminal, un résultat inférieur aux 78,2 % de GPT-5.5.
Anthropic a également souligné la sécurité améliorée du modèle, indiquant une réduction des tendances à la tromperie ou à l'utilisation abusive. Claude Opus 4.8 égale presque l'expérimental Claude Mythos Preview à cet égard, montrant des progrès significatifs dans l'alignement du comportement du modèle sur les normes éthiques.


















Commentaires 0
…