Denkt KI eigentlich gar nicht? Wissenschaftler lüften das Geheimnis hinter den „Reasoning“-Ketten
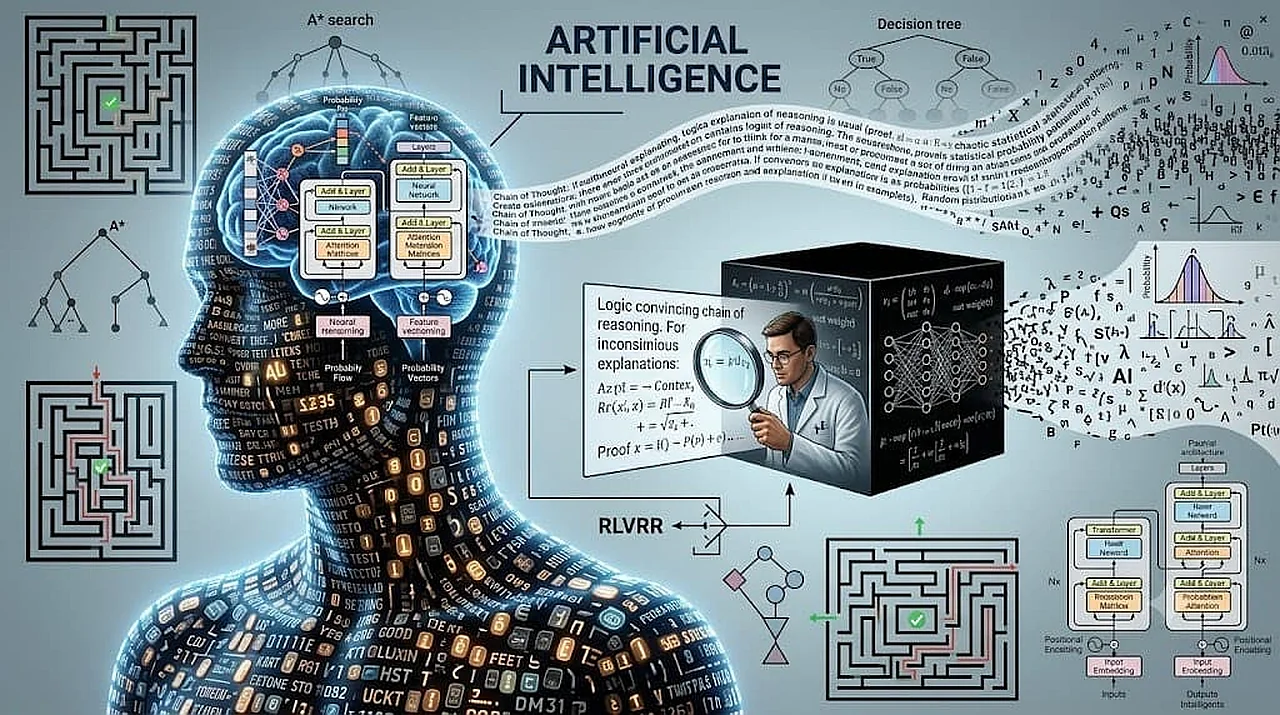
In letzter Zeit haben große Reasoning-Modelle (LRM) wie OpenAI o1 und DeepSeek R1 die Welt mit ihren scheinbar menschenähnlichen Denkfähigkeiten in Staunen versetzt. Eine neue wissenschaftliche Arbeit von Forschern der Arizona State University unter der Leitung von Subbarao Kambampati stellt diese Vorstellungen jedoch infrage. Die Wissenschaftler betonen, dass die langen „Chain of Thought“ (CoT) neuronaler Netze kein echter kognitiver Prozess, sondern lediglich eine statistische Manipulation sind. Dies berichtet Ixbt.com Nachrichten berichtet.
Nach Ansicht der Forscher erzeugen die logischen Sequenzen moderner KI-Systeme beim Nutzer die überzeugende Illusion, dass ein intellektueller Prozess stattfindet. Tatsächlich sagen diese auf der Transformer-Architektur basierenden Modelle lediglich den nächsten Token (Wortfragment) basierend auf dem vorherigen Kontext statistisch voraus. Diesen Prozess mit dem menschlichen Mechanismus des logischen Schlussfolgerns gleichzusetzen, gilt als wissenschaftlich falsch.
Der „Heureka“-Moment — reine Imitation
In der wissenschaftlichen Arbeit wird besonderes Augenmerk auf die Verwendung von sogenannten „Aha-Momenten“ durch KI-Modelle gelegt, also Phrasen wie „Ja, jetzt verstehe ich“, als ob sie das Problem plötzlich begriffen hätten. Wissenschaftler bezeichnen dies nicht als qualitative Änderung in den internen Berechnungen des neuronalen Netzes, sondern als bloße Imitation des menschlichen Stils in den Trainingsdaten. Technisch gesehen sind diese Systeme nur auf die endgültige richtige Antwort optimiert, während die Zwischenketten keiner semantischen Prüfung unterzogen werden.Laut ixbt.com nutzten die Forscher mathematische Aufgaben, wie das Verlassen von Labyrinthen und das Finden des kürzesten Weges, um ihre Hypothesen zu beweisen. Während der Experimente wurde ein unerwartetes Ergebnis festgestellt: Die Modelle fanden die richtige Antwort auch dann, wenn die Kette der logischen Erklärungen absichtlich falsch oder verwirrend gestaltet war. Dies zeigt, dass das System seine eigenen „Überlegungen“ nicht liest, sondern sie lediglich als zusätzliches statistisches Muster verwendet.
Ein weiterer interessanter Fall wurde in einem Experiment namens „no-maze instances“ beobachtet. Hierbei erhielt die KI eine extrem einfache Labyrinth-Aufgabe ohne jegliche Hindernisse. Dennoch generierten die Modelle mehrere Seiten an „Überlegungen“. Dieser Fall widerlegt die Ansicht, dass die Länge des Reasonings Rechenleistung oder Komplexität bedeutet. Lange Texte sind lediglich ein statistisches Artefakt, da komplexe Probleme in der Trainingsdatenbank mit langen Erklärungen einhergingen.
Das „Theater des Reasonings“ und seine Gefahren
Wissenschaftler warnen die KI-Branche davor, in die Falle eines „Theaters des Reasonings“ zu tappen. Die von den Systemen gelieferten überzeugenden Erklärungen können beim Nutzer ein falsches Vertrauen (false trust) wecken. Dies ist besonders in Bereichen wie Medizin, Ingenieurwesen und Rechtswissenschaft gefährlich, da ein Mensch physisch nicht in der Lage ist, dutzende von einer Maschine generierte Seiten logischer Ketten in Echtzeit zu prüfen.Die Autoren der Studie schlagen als Alternative den LLM-Modulo-Ansatz vor. Dabei werden Sprachmodelle nur als Hypothesengeneratoren eingesetzt, während ihre Richtigkeit durch externe, mathematisch strikte Algorithmen überprüft wird. Die Hauptschlussfolgerung ist, dass die Anthropomorphisierung von KI-Modellen gestoppt werden muss und ihre Qualität nicht an ihrem „inneren Monolog“, sondern an unabhängig verifizierbaren Ergebnissen gemessen werden sollte.

















Kommentare 0
…