Xitoy sunʼiy intellekt poygasida yangi bosqichga chiqdi: LongCat-2.0 taqdim etildi
Xitoyning Meituan kompaniyasi sunʼiy intellekt olamida shov-shuvga sabab boʻlgan LongCat-2.0 modelini rasman namoyish etdi. Bu yangilik shunchaki navbatdagi neyrotarmoq emas, balki toʻliq mahalliy xitoy chiplarida oʻqitilgan dunyodagi birinchi trillion parametrli yirik til modeli (LLM) sifatida tarixga kirdi. Mazkur loyiha Gʻarbning texnologik cheklovlariga qaramay, Xitoy oʻzining mustaqil hisoblash quvvatlariga tayanib, eng yuqori darajadagi dasturiy mahsulotlarni yarata olishini isbotlamoqda. Bu haqda Ixbt.com xabar beradi.
LongCat-2.0 oʻzining texnik koʻrsatkichlari bilan hayratda qoldiradi: model 1,6 trillion parametrga ega va 1 million tokengacha boʻlgan ulkan kontekstni qayta ishlay oladi. Taqqoslash uchun, bu bir vaqtning oʻzida bir necha jildli kitobni oʻqib chiqish va undagi maʼlumotlarni tahlil qilish bilan barobardir. ixbt.com maʼlumotiga koʻra, modelni oʻqitish jarayoni 50 mingta mahalliy ASIC-tezlatkichlaridan iborat klasterda amalga oshirilgan. Mutaxassislar ushbu infratuzilmani Huawei ekotizimi bilan bogʻlashmoqda, bu esa Xitoyning apparat taʼminoti sohasidagi mustaqilligini koʻrsatadi.
Agentlik imkoniyatlari va texnik innovatsiyalar
LongCat-2.0 shunchaki matn yozuvchi bot emas, balki murakkab vazifalarni bajaruvchi "agent" sifatida ishlab chiqilgan. U kod yozishi, tahrirlashi, turli API xizmatlari bilan ishlashi va koʻp bosqichli mantiqiy zanjirlarni amalga oshirishi mumkin. Modelning oʻquv bazasi 30 trilliondan ortiq tokenni oʻz ichiga olgan boʻlib, u koʻp tilli maʼlumotlar va dasturlash kodlari bilan boyitilgan. Bu esa uni global bozordagi eng kuchli modellardan biriga aylantiradi.Texnik jihatdan LongCat-2.0 "LongCat Sparse Attention" (LSA) mexanizmidan foydalanadi. Ushbu texnologiya modelga ulkan matnlarni qayta ishlashda faqat eng muhim qismlarga eʼtibor qaratish imkonini beradi, bu esa hisoblash murakkabligini keskin kamaytiradi. Shuningdek, model "Mixture of Experts" (MoE) arxitekturasiga asoslangan boʻlib, har bir soʻrov uchun faqat kerakli neyronlarni ishga tushiradi. Oddiy vazifalar kamroq resurs sarflasa, murakkab masalalar uchun barcha quvvat safarbar etiladi.
Modelning oʻqitilishida MOPD (Multi-Teacher On-Policy Distill) uslubi qoʻllanilgan. Bu jarayonda bir nechta ixtisoslashgan "ustoz" modellar yagona tizimga bilim beradi. Natijada LongCat-2.0 uchta yoʻnalishda yuqori natija koʻrsatadi:
- Agentlik ekspertlari — asboblar va API bilan ishlash;
- Mantiqiy ekspertlar — murakkab STEM va mantiqiy masalalar;
- Interaktiv ekspertlar — koʻrsatmalarga aniq amal qilish va xatoliklarni kamaytirish.
Raqobat va amaliy natijalar
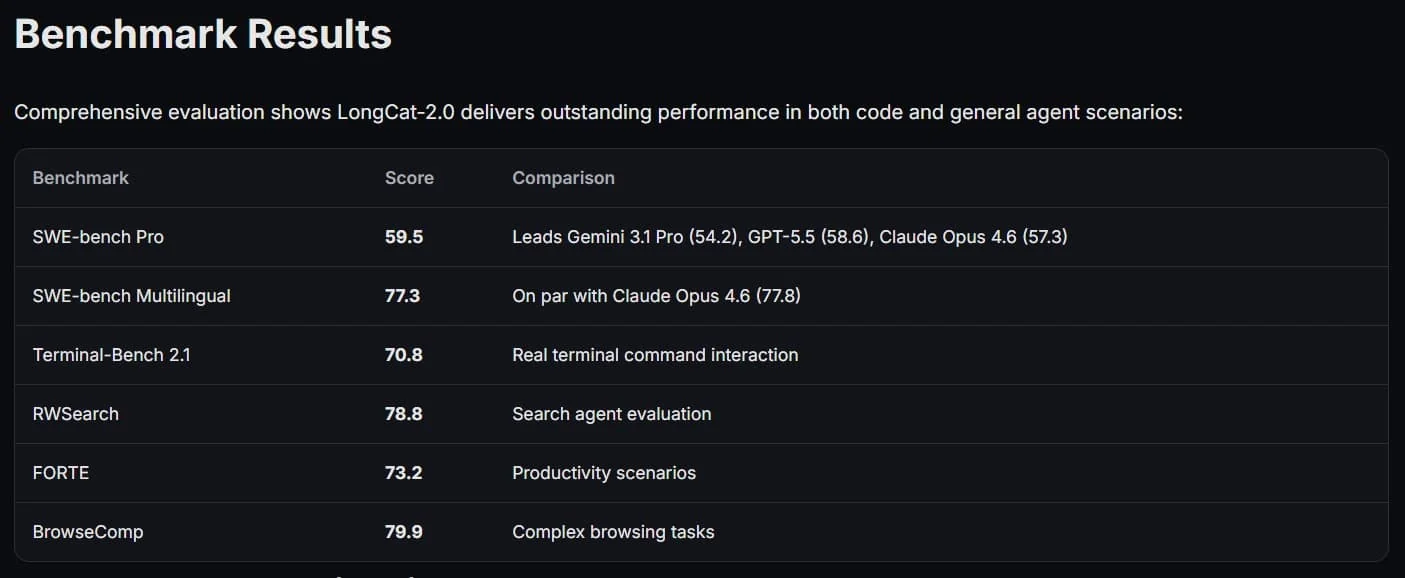
Oʻtkazilgan testlarda LongCat-2.0 oʻzining raqobatchilaridan qolishmasligini koʻrsatdi. SWE-bench Pro reytingida u 59,5 ball toʻplab, Google kompaniyasining Gemini 3.1 Pro modelidan oʻzib ketdi va OpenAI hamda Anthropic kompaniyalarining GPT-5.5 va Claude Opus kabi yetakchi modellari darajasiga yaqinlashdi. Ayniqsa, kod yozish va veb-agentlar bilan ishlashda uning natijalari yuqori baholandi.Amaliyotda LongCat-2.0 yordamida birgina tavsif asosida toʻliq veb-ilovalar yaratish, SQL-agentlarini qurish va Three.js kutubxonasida interaktiv 3D sahnalarni shakllantirish mumkin. Bu kabi yutuqlar Xitoyning sunʼiy intellekt sohasidagi strategik maqsadlari naqadar jiddiy ekanini anglatadi. Endilikda trillion parametrli modellarni oʻqitish faqat tajriba emas, balki amaliy reallikka aylandi, bu esa jahon texnologiya bozoridagi muvozanatni oʻzgartirishi tayin.






























Izohlar 0
…